AI Bash - Use openai's davinci model to write bash commands with human language
01/17/2023Intro to aibash
OpenAi's chatgpt and text-davinci-003 have captured the imagination of the world, with many people predicting radical transformations to software and wider the tech industry. I've been experimenting with pushing this technology to it's limits by making lower level tools backed by openai's text-davinci-003 model. One specific tool I've created: aibash is a simple bash script takes a prompt and generates a bash command, which is output to srderr before running. In this article I'll run through a few example shell tasks and attempt to accomplish them using Ai prompts, and then at the end I'll try to assess the value of prompting as a computer interface.
aibash prerequisites
aibash is a bash script, so you'll need:
That is all you need, this script calls a backend I'm working on called superfunctions, but this is still in development so I'll avoid talking about it for now. Warning: this tool can be destructive to your system, this is a POC so approach with caution
Example 1: Use posix find to search a directory for a files with more than 500 lines
Sometimes it's useful to find code that has a lot of lines, it helps you get acquainted with a repo, or find a good place to start refactoring. For this example I've chosen to use the react-routercode base, because it's a reasonably interesting code base, and it's a good size.
I really like using find, but it has so idiosyncrasies with the command line arguments that sometimes cause me to bumble around.
aibash find all files with more than 500 linesaibash performs really well here, combiningfind, wc andawk.
find . -type f -exec wc -l {} ; | awk '$1 > 500'This outputs a lot of files that aren't often relevant: tests, documentation, package lock files, etc…
Let's see if we can filter these out.
Example 2: Remove irrelevant files from previous example
aibash \
'find all files with more than 500 lines,' \
'only include files in ./packages that end in .ts or .tsx,' \
'and remove paths that contain word __tests__'
find ./packages \
-type f \( -name "*.ts" -o -name "*.tsx" \) \
-exec wc -l {} \; |
awk '$1 > 500 && $2 !~ /__tests__/'
1192 ./packages/react-router-dom/index.tsx
818 ./packages/react-router/lib/hooks.tsx
631 ./packages/react-router/lib/components.tsx
683 ./packages/router/history.ts
3223 ./packages/router/router.ts
1262 ./packages/router/utils.ts;
The command aibash generated is pretty impressive, the level of understanding these arguments is way beyond my casual understanding of find and slightly beyond my awk abilities. This is useful.
Example 3: Analyze a git repo to get a feel of the activity
I'm pretty comfortable with the git cli interface when it's commands that are part of my normal work flow (rebase, count commits between branches), but I often find myself looking up the exact syntax for the less common use cases.
I work at a large organization and often need to get quickly acquainted with repos internal or external. It can help to get a quick feel of the timeline of development and who the key developers are. Let's see if aibash can help by listing out the top contributors and separately get the number of commits by year.
aibash cwd is a git repo, list top 10 users by number of commitsgit shortlog -sn --all | head -10
1870 Michael Jackson
1161 Ryan Florence
389 Jimmy Jia
375 Tim Dorr
279 Chance Strickland
260 Matt Brophy
128 Mateusz Zatorski
93 Dan Abramov
77 Paul Sherman
61 Logan McAnshI got an error without the cwd is a git repo, but got good results after (shout out toreact-router team for the great work).
Now let's see if we can get the number of commits by year.
aibash 'cwd is a git repo, for each year output the number of commits'for year in $(git log --pretty=format:"%ad" --date=short | cut -d '-' -f1 | sort -u); do
echo "$year: $(git log --pretty=format:"%ad" --date=short | grep $year | wc -l)";
done
2014: 997
2015: 1540
2016: 960
2017: 596
2018: 247
2019: 190
2020: 155
2021: 503
2022: 516My first attempt worked but put year as the second column, which is unfashionable, probably it just gave me results according to the word order of the prompt. On my second try it gave me the desired results with a script I would find arduous to write even after some googling.
Example 4: Find and download top posts from reddit's /r/photos
In our final example I wanted to try and push the limits a bit. It's pretty easy to get aibash to download the images from reddit, but the default file name are meaningless. I want to use the post title in the file name. To deal with this additional complexity I thought it best to split it into a two part process:
1) Find images and titles and save them to a JSON file
aibash \
"using a normal safari user agent get top reddit posts of this month on /r/photos," \
"use json api," \
"get top 3," \
"find posts with the url attribute ends with extension jpg. " \
"using jq discard posts that dont have an image," \
"output json like [{ reddit_id: 'abcd', imageUrl: 'https://...jpg', title: 'a photo' }]" > images.jsoncurl \
-A "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1.2 Safari/605.1.15" \
"https://www.reddit.com/r/photos/top.json?t=month&limit=3" |
jq -r '.["data"]["children"] | map(select(.data.url | endswith(".jpg"))) | map({reddit_id: .data.id, imageUrl: .data.url, title: .data.title})'Besides having to add the user agent flag, I was able to get good results easily.
[
{
"reddit_id": "zuv1oc",
"imageUrl": "https://i.redd.it/xjzq16b5428a1.jpg",
"title": "Today marks one year sober. Merry Christmas to me!"
},
{
"reddit_id": "103y1dw",
"imageUrl": "https://i.redd.it/sjziqbxqh9aa1.jpg",
"title": "Hello."
},
{
"reddit_id": "zvbzr4",
"imageUrl": "https://i.redd.it/20v3dclkc58a1.jpg",
"title": "Big Sur in Autumn [6048x8064]"
}
]2) Parse that JSON file and download images contained
aibash 'read file images.json' \
'its an array [{ imageUrl, title }],' \
'loop over the element.' \
'in each each iteration use jq to parse out and assign variables $title (remove non letters) and $imageUrl,' \
'and download $imageUrl to the disk like $title.jpg'
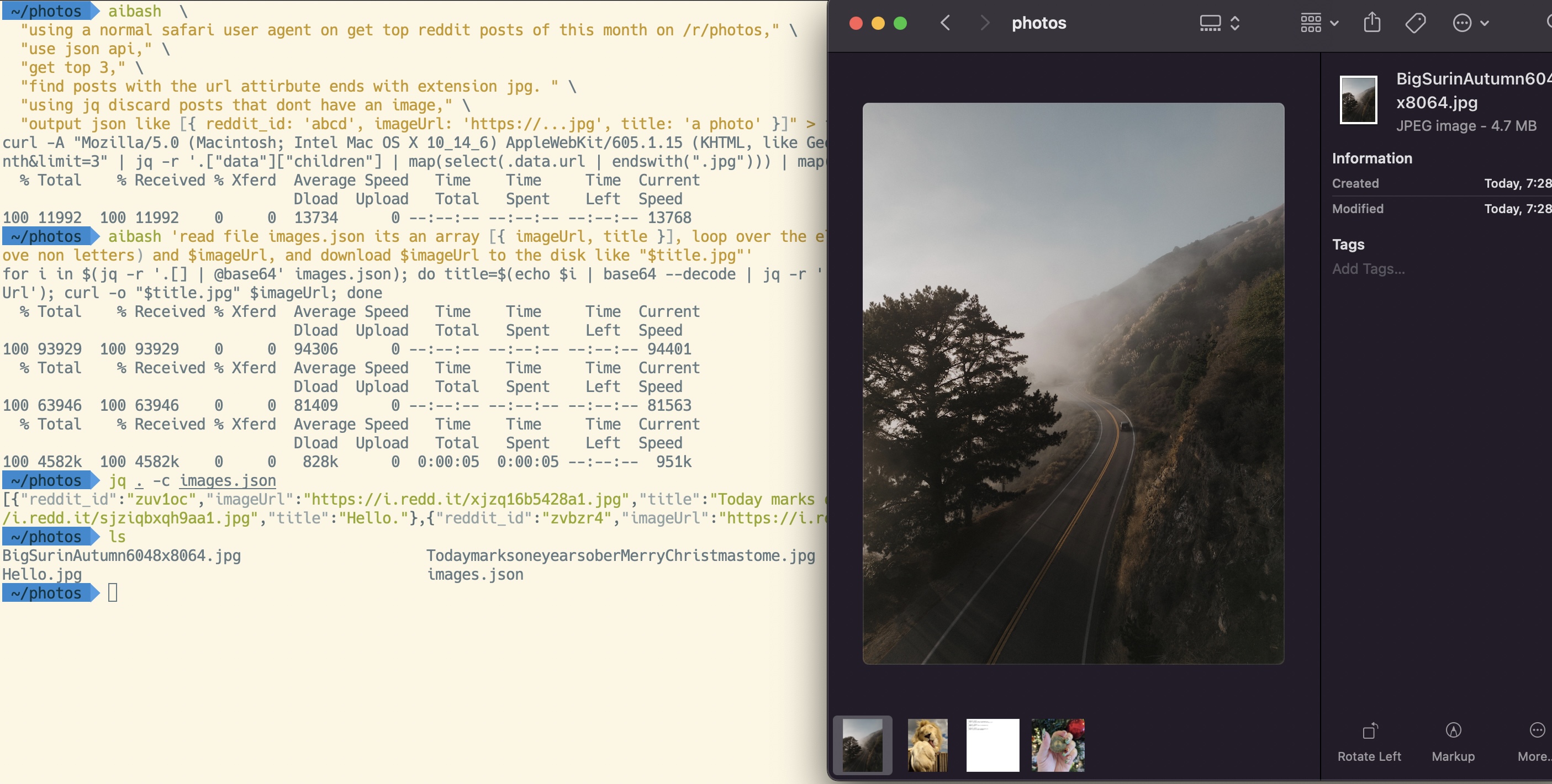
Above you can see the screenshot of the script in action. It's kind of cool, but at the same time the second prompt took many attempts to get right. The Ai really struggled to associate the title to the url, the only solution I could come up with was to be very explicit about the variable assignment in the loop. It's a lot of fun to see it in action but this example was definitely not an efficient way to get the job done.
Takeaways
The quality of results are impressive, it's clear that in the future technical tasks will be increasingly accomplished with AI assistance. While this tool is just a proof of concept it is a good opportunity to assess the pros and cons to prepare for the Ai entrenched future.
This new technology can be intoxicating so let's attempt a more sober assessment.
Naturally the prompts require more typing, on the other hand bash is unforgivingly picky. One typo in bash and we get an aggressive error. The ai is unbothered by typos, syntax errors and I even got identical results when I retyped the prompts in spanish.
Do I find myself grabbing for this tool when I need a oneliner? Actually yes, particularly with commands that have a lot of arguments, or commands I'm vaguely familiar with.
However, like most developers I slowly iterate to an ultimate solution. Prompt iteration differs from other higher level abstractions because small changes can result in very different results, which leaves me less confident in the iterative development process.
Well that is all I have for now, stay tuned for more.