PostgreSQL JSON
01/10/2023
Background
Generally Api development involves querying a database and outputting JSON. Traditional web frameworks often encourage using ORMs which can lead to an unnecessary amount of queries and leaves the application code to combine and massage the data into a format the client expects. For the last few years I've been experimenting with generating the JSON directly in PostgreSQL. In this article I will show an example of how this can be done and then discuss the drawbacks I've encountered.
PostgreSQL JSON support landed in version 9.2 (2012) and JSONB in 9.4 (2014). This support came with many powerful JSON functions and aggregate functions that enable developers to shape JSON payloads in a relational context. In this article I will be using JSON and JSONB interchangeably, but it's almost always better to use JSONB.
I have a few production apps that use the PostgreSQL JSONB approach and it's now my default way to write apps that require a relational database. I've been surprised by the lack of maintenance needed even when the complexity is very high. The nature of SQL as a declarative language is to describe the data you want, this contrasts with application code where you imperatively describe the steps that mutate state in order to arrive at the desired result. The imperative approach is more likely to be incorrect because it involves a timeline of changes, and this timeline is another thing to get wrong. Sql's declarative nature, specialized JSON functions and first-class aggregation support provide an elegant platform to generate JSON straight from the database.
Example: Background and DDL
Let's look at a contrived example of bank users that can have multiple accounts of different types (checking, savings, etc).
create table bank_users(user_id serial, name text not null, created_at timestamp default now());
insert into bank_users (name) values ('John Smith');
insert into bank_users (name) values ('Mary Jones');
create table bank_accounts (
account_id serial,
user_id int not null,
balance decimal not null default 0,
type varchar(255) not null default 'checking'
);
insert into bank_accounts (user_id, balance, type)
values (1, 500.00, 'checking'),
(1, 4300.00, 'saving'),
(2, 1200.00, 'checking');Given the above PostgreSQL DDL we want to query a list of users probably as an object and their accounts as an object with the types as a key.
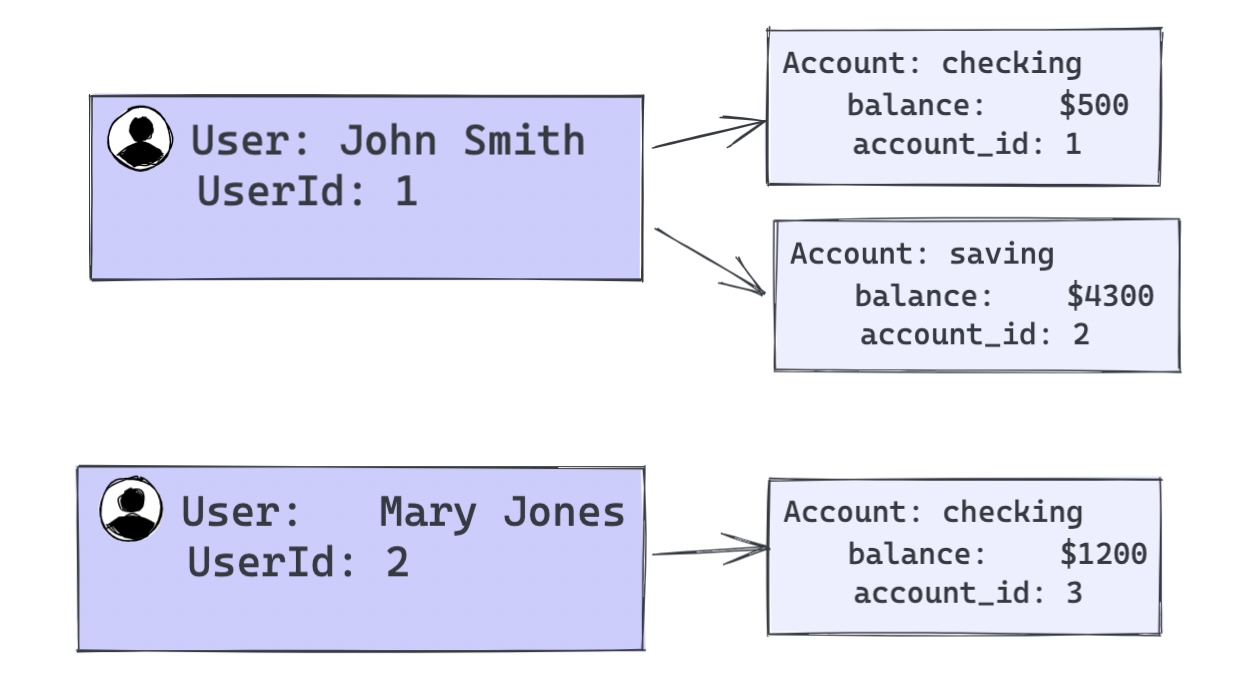
Example: Query
The traditional MVC approach would be to have a Usermodel and an Account model, and then have the controller combine both models before rendering our desired JSON payload. Instead we will construct a query using CTEs (not strictly necessary but makes the code more fashionable) and JSON functions.
with accounts as (
select
a.user_id,
jsonb_object_agg(
a.type,
jsonb_build_object(
'balance', a.balance,
'id', a.account_id
)
) as accounts
from bank_accounts a
group by a.user_id
),
users as (
select
u.user_id,
jsonb_build_object(
'accounts', a.accounts,
'user_id', u.user_id,
'name', u.name,
'created_at', u.created_at::date
) as data
from bank_users u
left outer join accounts a
on u.user_id = a.user_id
)
select jsonb_agg(u.data) as data
from users u
Example: accounts CTE
The above code is using two CTE blocks. Let's start by analyzing the first: accounts. This query gets a single row for each user where one column is the user_id and the other is a JSONB object of the user's accounts. The magic here is in the combination of group by and jsonb_object_agg, which groups the accounts by account type and combines them into a single JSONB object. I also used jsonb_build_object to remove redundant keys from the accounts, but this isn't necessary if you don't mind the extra data. Maybe the image below will help you visualize this.
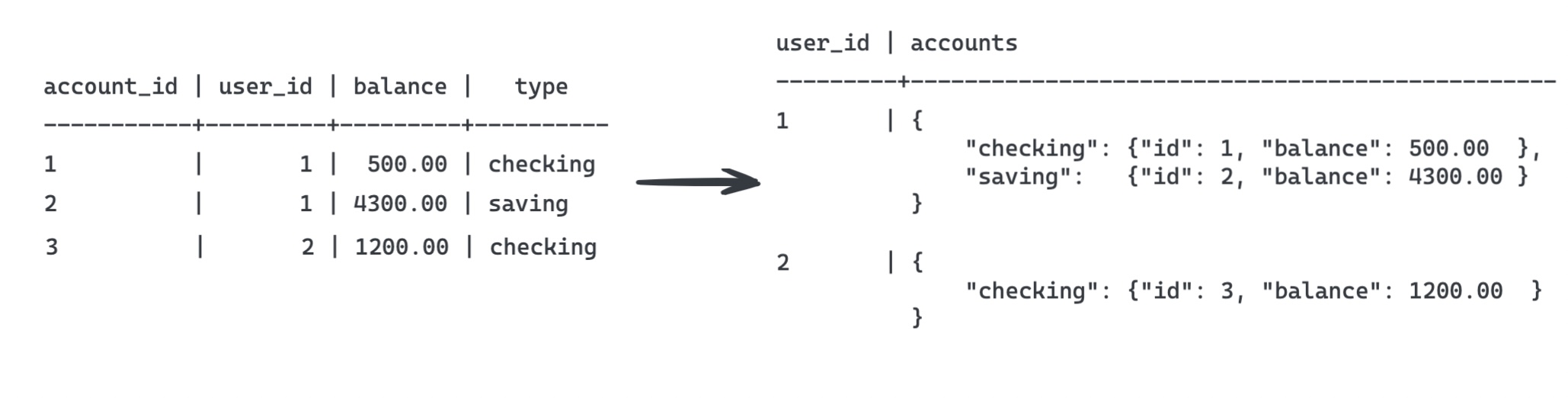
Example: users and primary query
The second CTE block, users is much simpler. We use jsonb_build_object, a function that simply takes a list of key value pairs and outputs JSONB, and then combines it with a simple left outer join in oder to keep users that have no accounts.
Finally we end with the primary query, which contains jsonb_agg. This is an aggregate function that is commonly used with group by. Here we omit group by which has the affect of grouping everything, all rows get merged into a single JSONB array.
JSON output
[
{
"name": "John Smith",
"user_id": 1,
"accounts": {
"saving": { "id": 2, "balance": 4300 },
"checking": { "id": 1, "balance": 500 }
},
"created_at": "2023-01-16"
},
{
"name": "Mary Jones",
"user_id": 2,
"accounts": {
"checking": { "id": 3, "balance": 1200 }
},
"created_at": "2023-01-16"
}
]Gotchas
The example query is pretty simple, but in the real world it can get complex. We can help tame the complexity by continuing with the CTEs or we can go further by using user-defined functions that return JSONB or tables.
The biggest gotchas I've encountered that weren't immediately obvious were that empty aggregations return null in places I expected them to return empty arrays, this can be solved with thecoalesce function. More trickier than that are the problems that arise while dealing with aggregation. While these are specific to JSON I encounter them often enough to mention them here. Sorting of aggregations is not affected by row level order by but instead uses aggregation level order_by_clause to determine the order of the output. Lastly there are some scenarios where unwanted nullvalues pop up in aggregated arrays. PostgreSQL has a special filter syntax to filter out null values from aggregations.
Drawbacks of using JSON in PostgreSQL
Testing these JSON functions is a strange beast, of course it's not different from regular sql testing, but sql testing is rare and application code testing is not, so it's worth pointing out we suffer from a deficit of testing tools that would otherwise be available in application code.
The other downside is that it's not obvious where to put the code if you really embrace this approach. The obvious first step is to just use really long lines of sql in your application code, but this is not ideal. There is nothing wrong with this, but eventually I started using postgresql functions to encapsulate the sql. This is a good approach but comes with its own set of problems around deployment, versioning and again testing. Postgresql functions are out of the scope of this article, but maybe I'll write about them in the future.
Conclusion
I've used this approach in production for complex use cases and have had great results:
- Code is much simpler
- Lower latency to query
- SQL code tends to be more correct
- SQL code tends to require less maintenance
- I'm much more confident in my ability to write complex queries